Pytorch |
您所在的位置:网站首页 › pytorch 调用核函数 › Pytorch |
Pytorch
|
文章目录
最大值池化层平均值池化层自适应平均值池化层代码实现
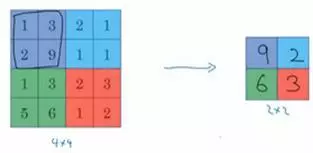
还是用上次的小实例 ,这次加入三种池化层做练习。 关于池化层的基础概念可以看这里。 我之前以为池化层也叫下采样,但这样说并不严格,只是大家都这么说,我刚知道,其实采样层包含池化层。某种卷积层也叫采样层。 最大值池化层选择每个小区域的最大值作为特征放到结果矩阵,像下面这样。
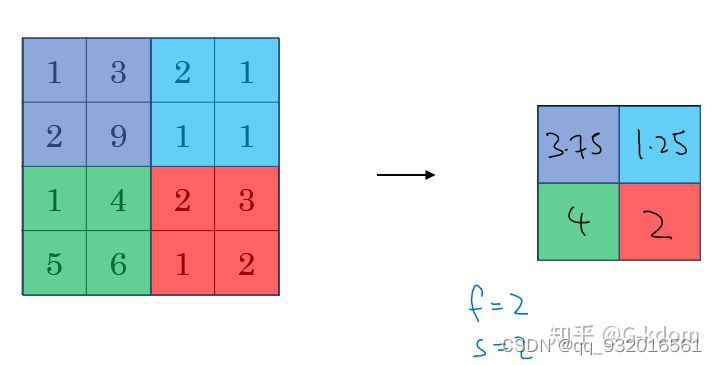
就是从这个区域中算出平均值加入结果集。 像下面这样。
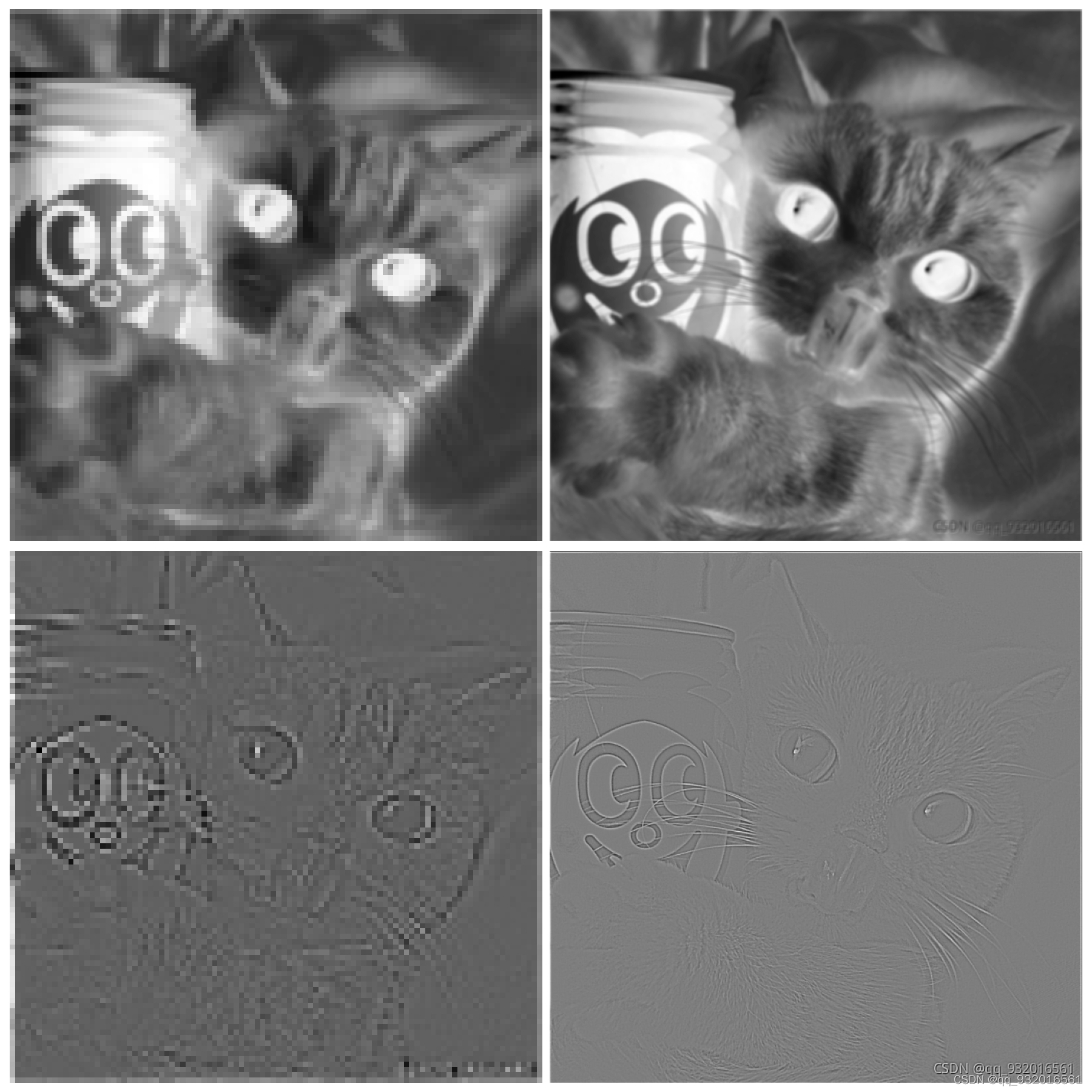
自适应池化Adaptive Pooling与标准的Max/AvgPooling区别在于,自适应池化Adaptive Pooling会根据输入的参数来控制输出output_size,而标准的Max/AvgPooling是通过kernel_size,stride与padding来计算output_size。 adaverage_pool = nn.AdaptiveAvgPool2d(output_size=(100,100)) # 输出大小的尺寸指定为100*100 pool_out = adaverage_pool(image_out) 代码实现沿用上一次的代码 直接加入池化层. ## 池化层加入 from copy import deepcopy from PIL import Image import torch import matplotlib.pyplot as plt import numpy as np from torch import nn image = Image.open('../data/cat.png') image = image.convert("L") image_np = np.array(image) h, w = image_np.shape image_tensor = torch.from_numpy(image_np.reshape(1, 1, h, w)).float() kersize = 5 ker = torch.ones(kersize, kersize, dtype=torch.float32) * -1 temp = deepcopy(ker) ker[2,2] = 24 conv2d = torch.nn.Conv2d(1, 2, (kersize, kersize), bias=False) ker = ker.reshape((1, 1, kersize, kersize)) conv2d.weight.data[0] = ker conv2d.weight.data[1] = temp image_out = conv2d(image_tensor) # 添加池化层----最大值池化 # maxpool = nn.MaxPool2d(2,stride=2) # pool_out = maxpool(image_out) # 添加池化层---平均值池化 # average_pool = nn.AvgPool2d(2,stride=2) # pool_out = average_pool(image_out) # 添加池化层---自适应平均池化层 adaverage_pool = nn.AdaptiveAvgPool2d(output_size=(100,100)) # 输出大小的尺寸指定为100*100 pool_out = adaverage_pool(image_out) # print(image_out.data) # print("=" * 20) # print(image_out.detach().numpy().shape) # 仅仅将tensor数据转为numpy数据 x = torch.linspace(-6,6,100) # -6到6分成了一百份 返回张量类型 print(type(x)) print(x) # print(pool_out.shape) pool_out_min = pool_out.squeeze() # print(pool_out_min.shape) image_out = image_out.squeeze() # 画图之前看一下数据维度,在压缩之前是四维张量 torch.Size([1, 2, 357, 357]) # 压缩之后是三维张量 torch.Size([2, 357, 357]) 这里有两个 (357*357) 一个是普通卷积 一个是边缘提取 # 给到最后plt画图的时候需要numpy类型数据。 所以直接[0] 和[1] 提取出来。 #结果对比 一组是普通卷积和卷积+池化 另一组是边缘检测和边缘检测+池化 plt.figure(figsize=(18,18),frameon=True) plt.subplot(2,2,1) # 你显示出来的图如何规划, 规划为2行2列 从左到右,从上到下,编号 plt.imshow(pool_out_min[1].detach(), cmap=plt.cm.gray) # 数据有梯度 使用detach方法提取 plt.axis('off') plt.subplot(2,2,2) # 加入池化层的普通卷积操作 plt.imshow(image_out[1].detach(), cmap=plt.cm.gray) plt.axis('off') plt.subplot(2,2,3) # 边缘检测 plt.imshow(pool_out_min[0].detach(), cmap=plt.cm.gray) plt.axis('off') plt.subplot(2,2,4) # 加入池化层的边缘检测 plt.imshow(image_out[0].detach(), cmap=plt.cm.gray) plt.axis('off') plt.show()最大值池化, 四个图对比 分别是: 普通卷积+池化 --------------- 普通卷积 边缘检测+池化 --------------- 边缘检测
自适应平均值池化
|
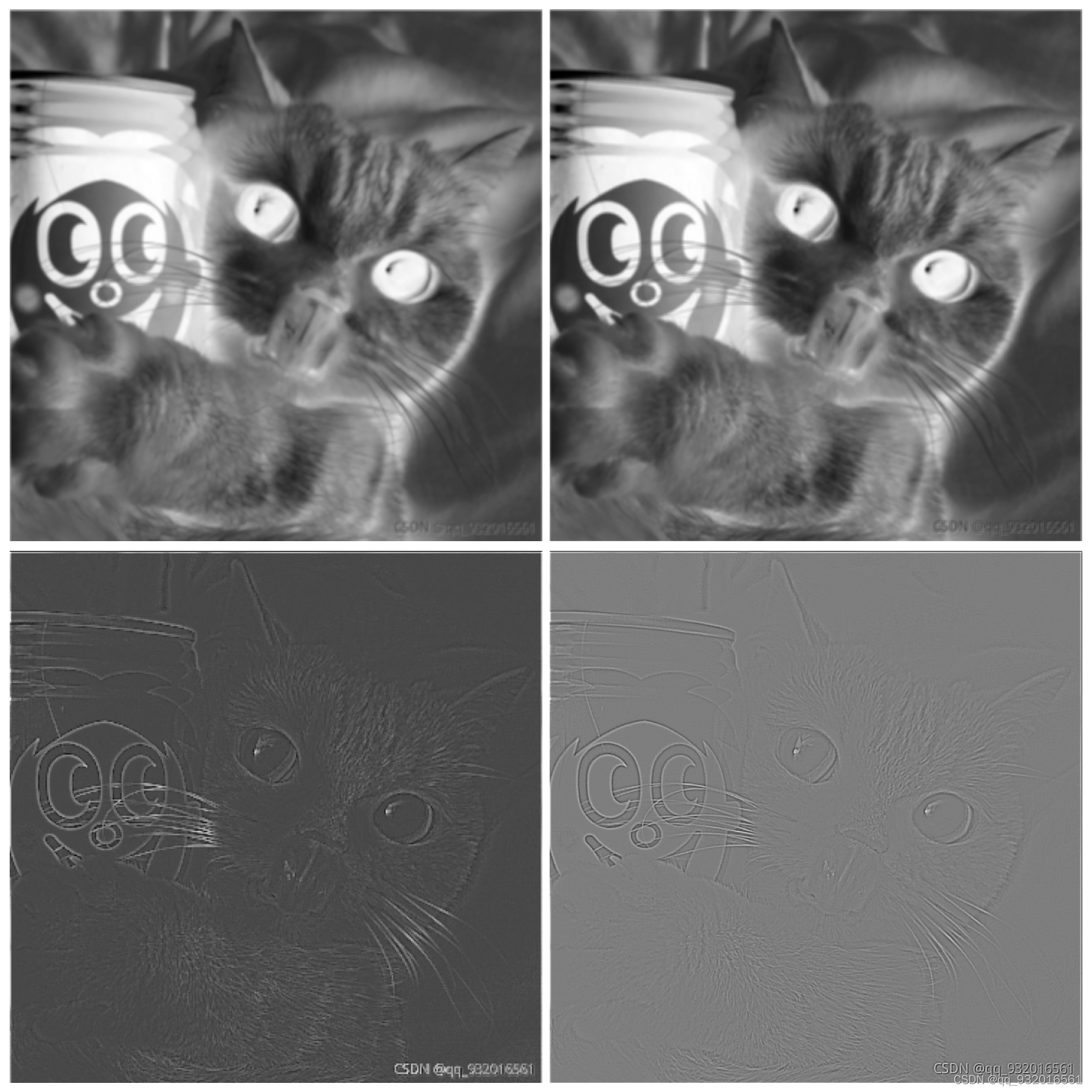 平均值池化
平均值池化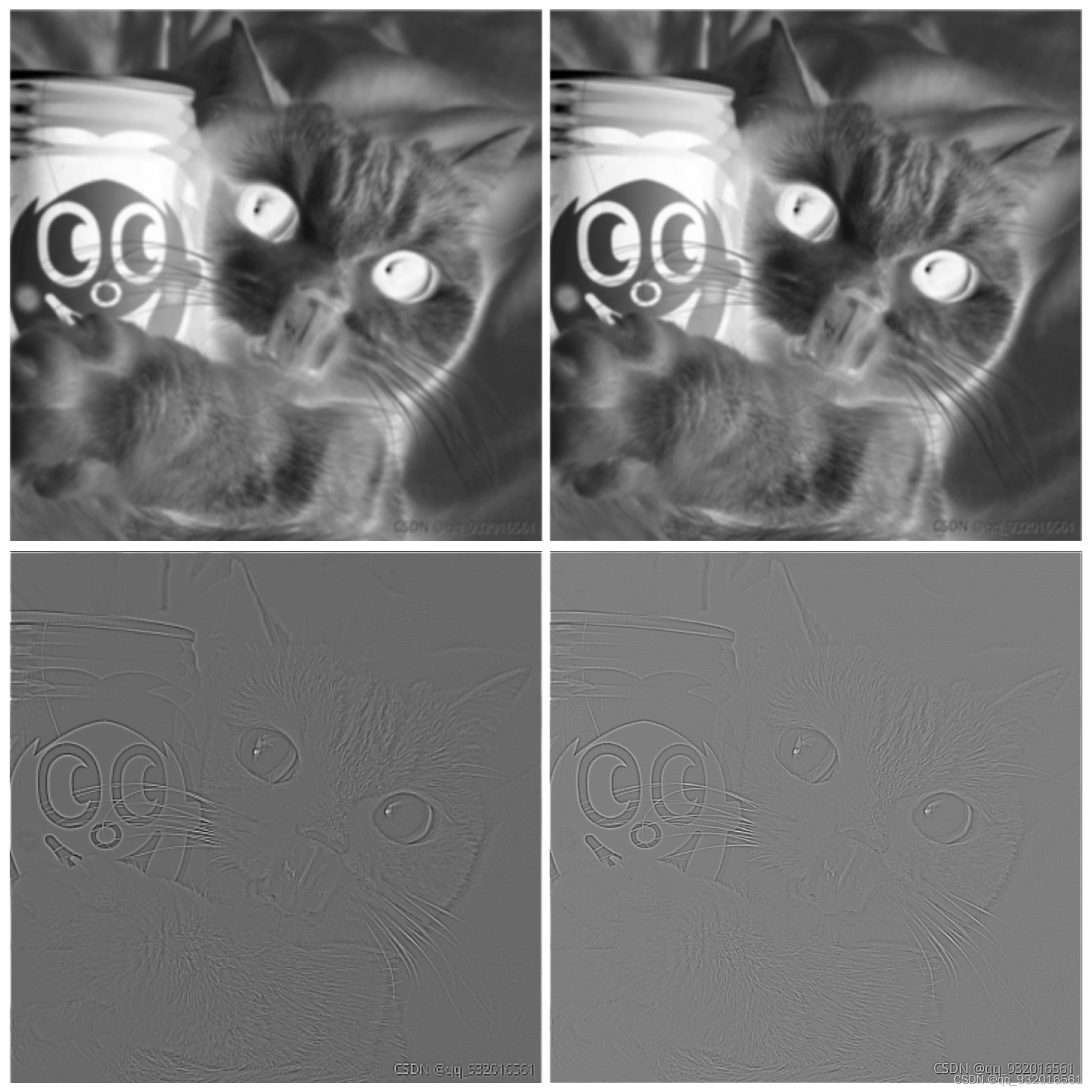
【本文地址】
今日新闻 |
推荐新闻 |